
Proprietary LLM architecture
for market intelligence.
QANDY is powered by a proprietary, self-trained market LLM designed to interpret liquidity, volatility, market structure, sentiment, risk, and cross-market conditions — and translate them into structured, explainable insights for users and platforms.
Not a bot. Not a signal group. A proprietary market LLM layer.
The intelligence layer, broken into its components.
Six interlocking systems convert raw market data into structured, decision-ready intelligence — delivered into the trader's existing workflow.
QANDY Insights.
Real-time AI market summaries covering liquidity, volatility, sentiment, market structure, directional pressure, key levels, and risk context.
Liquidity & Market Depth.
Understand where liquidity is building, thinning, clustering, or becoming vulnerable across assets and venues.
Asset-Level Intelligence.
AI-generated rundowns for individual assets, explaining what is happening, why it matters, and what levels or risks to watch.
Risk Intelligence.
Risk intelligence highlights volatility, crowding, invalidation zones, regime changes, and conditions that may require caution before a user acts.
Browser-Native Delivery.
Browser-native and exchange-integrated delivery means QANDY insights appear where users already research and trade — without requiring another dashboard.
Platform-Ready Infrastructure.
Built for clear, explainable market interpretation at scale. Designed for exchange integrations, Chrome extension distribution, platform licensing, and cross-market expansion.
Qandy 1.0 27B vs. frontier foundation models.
QANDY is a 27B-parameter domain-specialised model — orders of magnitude smaller than frontier general-purpose LLMs. The relevant comparison for a market-intelligence engine is mathematical and quantitative reasoning, where Qandy 1.0 27B punches well above its weight class.
| Benchmark | Qandy 1.0 27B | Claude Sonnet 4.6 | GPT-5.4 | Gemini 3.1 Pro | DeepSeek 3.2 | Measures |
|---|---|---|---|---|---|---|
| GPQA Diamond | 79 | 50 | 57 | 69 | 52 | Graduate-level STEM reasoning |
| HMMT Feb 2025 | 64 | 60 | 84 | 51 | 56 | Competition-grade math |
| ERQA | 74 | 80 | 89 | 66 | 58 | Numerical / estimation reasoning |
| SWE-bench Verified | 73 | 58 | 55 | 85 | 43 | Algorithmic code reasoning |
| BrowseComp | 77 | 93 | 92 | 89 | 50 | Web-search / retrieval over noisy sources |
| IFBench | 60 | 48 | 88 | 73 | 48 | Instruction-following |
Scores reported as percentage on the corresponding public evaluation suite. Frontier-model scores from public technical reports and third-party leaderboards; Qandy scores from internal evaluation under identical prompt protocols. Higher is better.
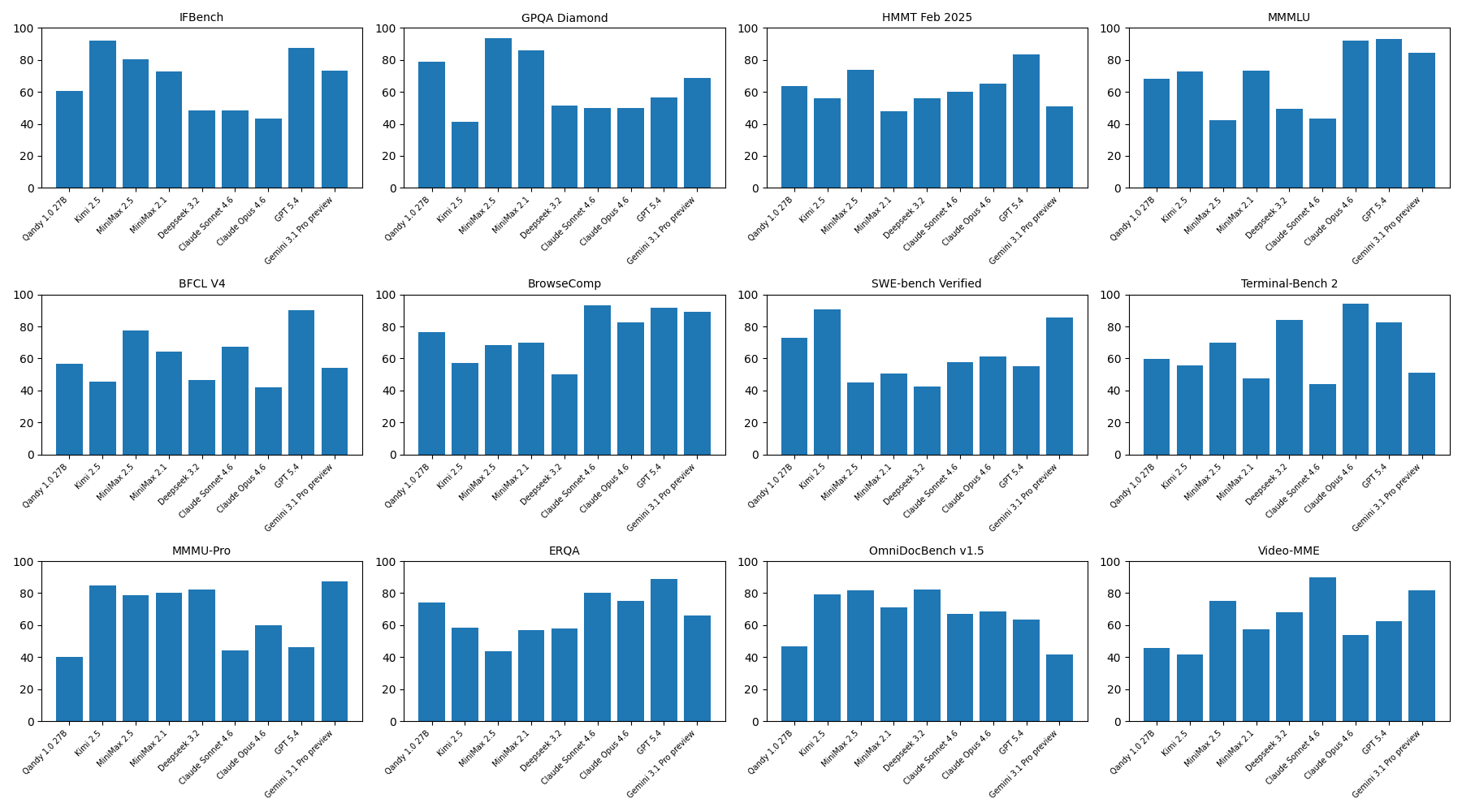
Qandy 1.0 27B vs. Kimi 2.5 · MiniMax 2.5/2.1 · DeepSeek 3.2 · Claude Sonnet/Opus 4.6 · GPT-5.4 · Gemini 3.1 Pro preview · Higher = better
Mathematical reasoning is the trading-relevant capability.
Trading is fundamentally a numerical-reasoning task. A 27B model that clears 70+ on GPQA Diamond, ERQA, and SWE-bench Verified — against frontier models 10–100× larger — is the efficiency profile you want running tick-by-tick.
Vertical models beat generalists at the actual job.
Public AI-trading benchmarks (Nof1 Alpha Arena, ai4trades) have shown that generic LLMs underperform at live market interpretation. QANDY is built around that finding — specialisation, not size.
Cost-of-inference is a unit-economics story.
A 27B model runs orders of magnitude cheaper than a frontier model on the same hardware. That matters when an intelligence layer is being delivered into the browser, 24/7, across many users.
How a market read becomes a rundown.
QANDY's intelligence pipeline is a sequence of specialised stages: data ingestion, signal extraction, contextual reasoning, risk framing, and language synthesis.
- 01Live data ingest across venues, instruments, and macro feeds.
- 02Signal extraction: liquidity, vol, structure, funding, flow.
- 03Multi-agent reasoning: technical, macro, risk perspectives.
- 04Risk framing: confidence, invalidation, regime.
- 05Language synthesis: concise, decision-ready rundown.
- 06Delivery: browser, API, partner integration.
An intelligence layer that ships into your workflow.
Try the Chrome extension, or talk to us about API access and platform integration.